转载公众号:Bella的技术轮子
1.项目立项
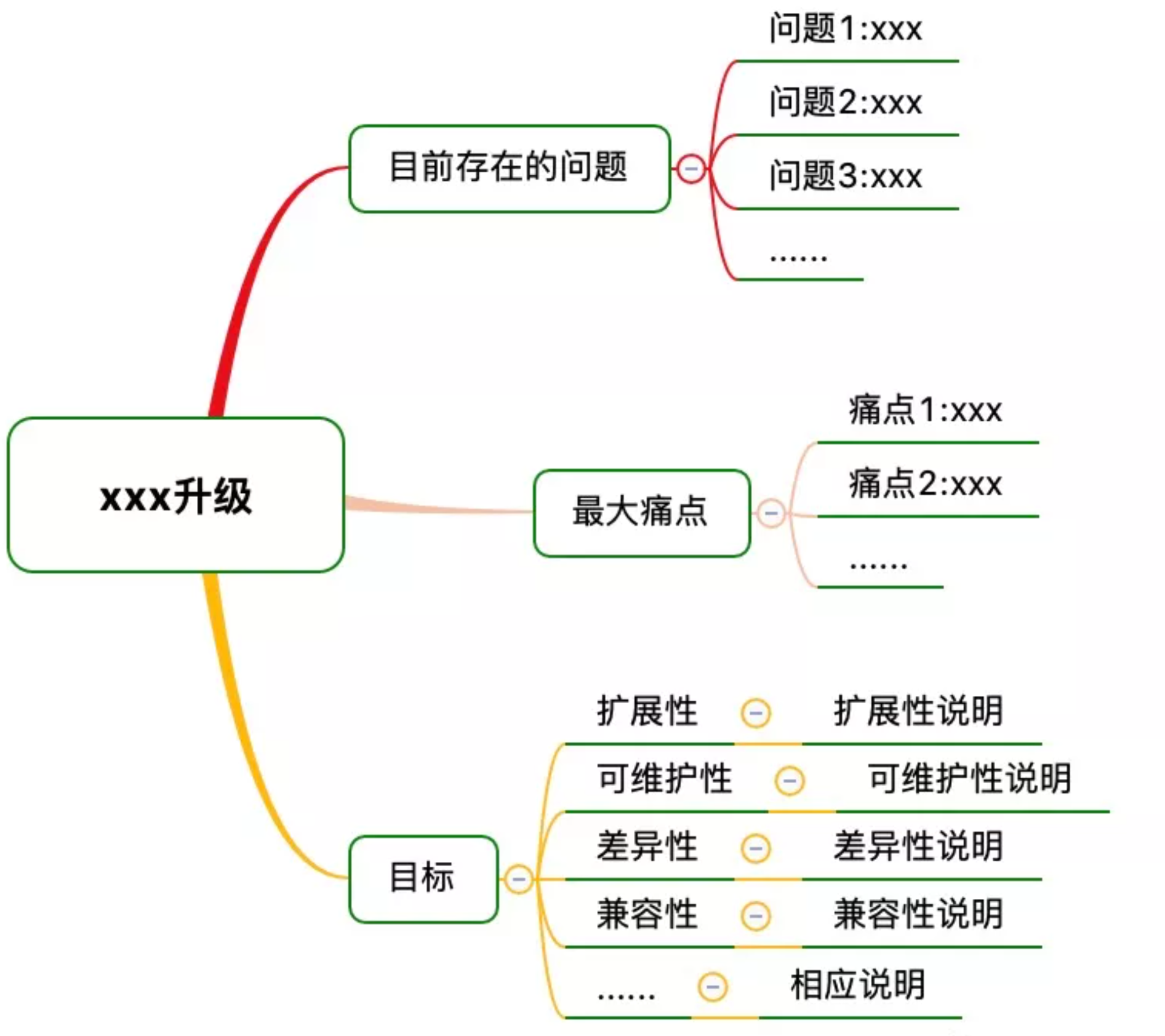
做一个项目之前,你要清楚为何要做这个项目,这个项目的价值和意义在哪里?如果是现有版本的大升级,那你还需要清晰的知道目前版本存在哪些问题,痛点是什么,扩展性如何,可维护性如何等等。同时还要确定升级后的版本的目标,只有目标确定了,后面技术方案选型的时候,你才会知道应该选取哪种技术方案,因为你选的技术方案,要能足够实现你的目标。
对于中台项目而言,还要考虑2个问题,即兼容性和差异性。所谓的兼容性,即指升级后的版本是否可以无缝兼容新接入一个行业?接入成本有多高?是否可以把一部分接入工作交由产品 or 运营同学来做,解放一部分技术同学劳动力?所谓差异性,即指升级后的版本是否可以支持不同行业间存在的差异,是否可以做到相互隔离,互不影响。
一般情况下,我会选择用思维导图来表达这些信息,图往往会比文字更简明直观一些,TL们的接受度也更高一些。
2.技术预研
这一阶段的主要目的就是基于上一阶段确定的目标,调研哪些技术可以支撑你实现这个目标,这些技术理论上的可行能否最准转变为落地上的可行,可以拿当前业务场景以及数据做一个推演,数据推演ok之后,可以再做一个小的可以运行的demo,以证明该技术真正可以用在此项目中。
此阶段需要产出各个技术选型的数据推演图,如果推演过程比较复杂的话,也可以考虑再产出一份比较详细的Excel样式的数据推演图,每一个步骤数据如何变化都要体现出来。另外,还需要产出各个技术选型可运行的demo。最后,需要产出各种技术选型的对比,表格形式或思维导图形式都可以,切忌纯文字。基于上述对比,确定最终的技术选型,然后就可以开始技术方案的编写啦~
3.技术方案编写
私以为技术方案应该包含以下几部分,业务背景、场景分析、系统架构、应用架构、系统流程图、领域模型设计、存储模型设计、全局可用定义、功能模块设计、接口定义、项目里程碑等等,如果是需要出海的项目,还需要考虑下本地化方式、时区偏移、部署方式等等。
3.1 业务背景
业务背景主要是交代下做这个项目的背景,即为什么要做这个项目,基于一个什么样的业务背景,也可以把【1.项目立项】中画的思维导图直接放在这一pa。
3.2 场景分析
场景分析则主要是讲这个系统有哪些应用场景,如果能够列举出业务方的真实诉求,那是最好不过了。然而大多数程序员的生活,并不会直接对接业务方同学,而是对接产品经理。
3.3 系统架构
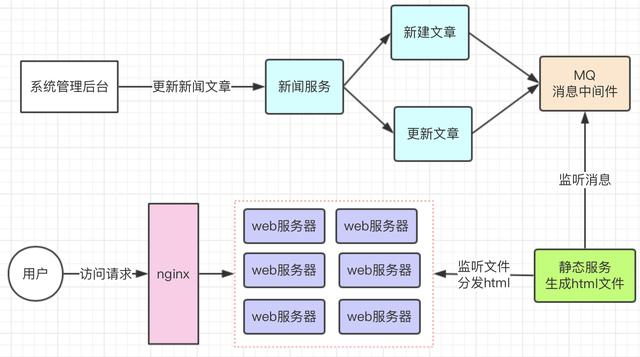
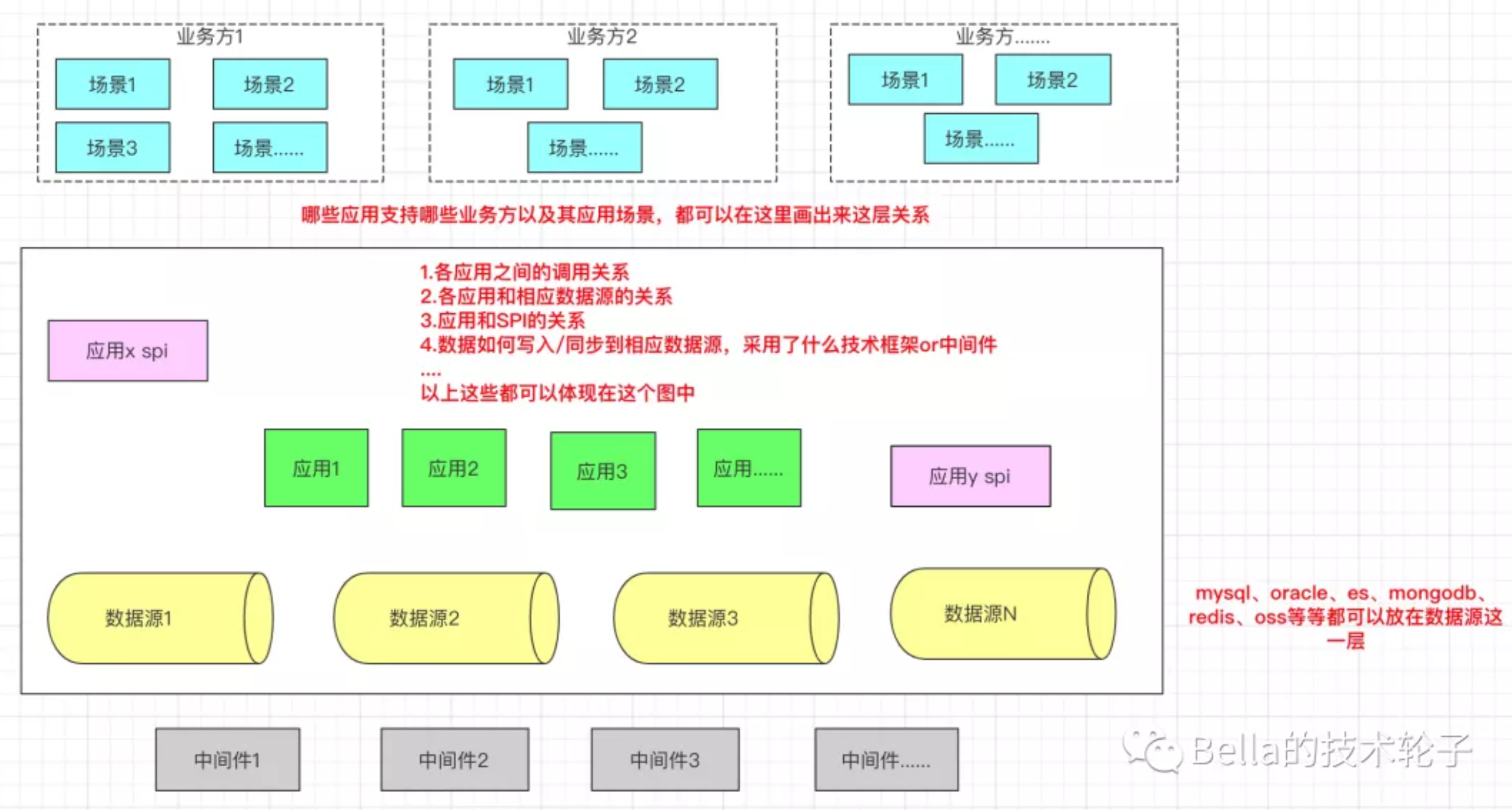
系统架构推荐以图的方式来展示。开局一张图,剩下全靠讲,也不是不可以哈。Bella酱就有过这种经历,开局我放了一张图,然后看着大佬们讲了3个多小时。佩服佩服,那次经历也让我懂得,表达方式是何等重要。一般情况下我会这么画系统架构图,主要侧重于表达用了哪些中间件、什么数据源、什么应用、开放什么SPI、以及这其中各组件之间是如何交互的,最终可以支撑哪些业务。
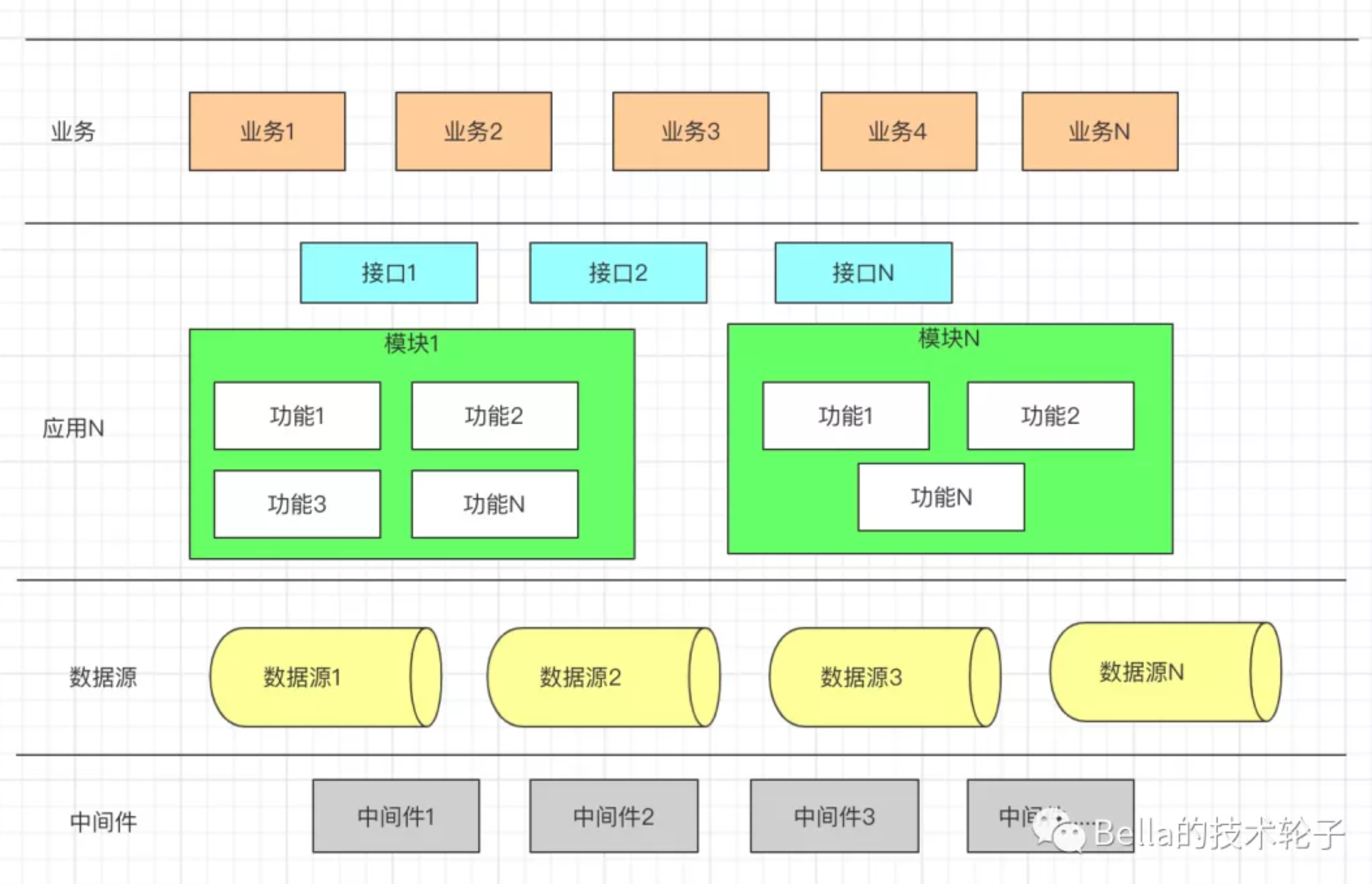
3.4 应用架构
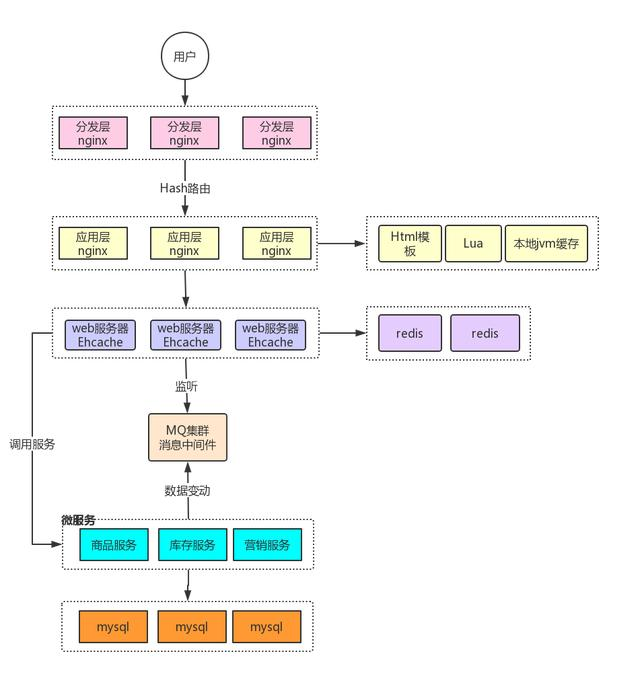
应用架构仍然推荐图的方式来表达。我一般这么画应用架构图,主要侧重于表达应用由哪些模块组成,每个模块包含哪些功能,各模块之间的层次关系,哪些应用包含哪些模块。另外,这张图中也是可以把用了哪些中间件、什么数据源,支持哪些业务场景画上的,这样这张图会更完整一些,即使不看系统架构图,单单看这一张图,也是可以明白整个项目的设计的。
3.5 系统流程图
系统流程图以流程图为主,可以辅以文字说明,或者表格说明,由于这个和业务逻辑紧密相关,此处不再举例。
3.6 领域模型设计
领域模型设计,这一阶段是非常有必要的,先确定领域模型,后再根据领域模型确定存储模型,并非所有的领域模型都要转换为存储模型,从而保存到数据库中。领域模型设计过程中,要十分清楚系统整体流程图,可以结合上个阶段的系统流程图,来推演一下,根据这些领域模型是否可以推演出系统的正常正确运行。图为主,辅以必要的文字说明此领域模型设计如何让系统运行即可。
3.7 存储模型设计
存储模型设计,需要详细到表中每个字段的设计,字段类型、是否为主键、是否需要建索引、是否可为空、是否为分表字段等等。表结构设计表格展示即可。存储模型设计,还是建议图片的形式表达,方便展示各表之间的关系。
3.8 全局可用定义
全局可用定义,主要定义一些通用的方法、枚举类、共同的约定等,以避免各个应用or各开发人员定义一套自己的方法、枚举等,以确保同一个字段or同一个方法等在系统内唯一。
3.9 功能模块设计
功能模块设计,即各模块的详细设计,这里应该尽可能详细,可以举一些例子,确保负责此模块开发的同学看文档即可明白要做什么,以及如何做。必要的话,可以各模块再出一个详细的技术方案。
3.10 接口定义
接口定义,呐,不多做解释,记得写清楚入参、出参、接口名字,入参和出参记得用自定义类来接收,不要忘记实现序列化哟~
BaseResult、isSuccess、getData、getErrorMessage、buildErrorResponse、buildSuccessResp这些基础的类和方法也不要忘记呀!
3.11 项目里程碑
项目里程碑,即项目的时间节奏,例如开发时间、联调时间、提测时间、发布时间等,此时也应该确定各种资源了,确保相关同学可以在你计划的时间范围内投入项目中。
3.12 其他
如果你的项目需要出海,那你还需要考虑系统的部署方式、本地化、时区偏移、系统所需中间件是否支持等等。
4.项目过程把控
只有好的方案,项目过程把控不到位,最终也是无法交付一个令人满意的产品的。那如何才能使项目按照既定计划有序进行,同时又能保证交付的质量呢?
作为一个项目的owner,你需要做:
- 技术方案要切实可行
- 明确整个项目的时间节奏,每个阶段应该交付什么可衡量的结果,每个阶段之间的关联性,不能按时交付的影响
- 明确每个人所做的事情,每个事情需要做多久,交付结果是什么
- 是否可阶段性提测,阶段性验证
- 识别项目中存在的风险,风险是否可控
- 大促封网,和上下游依赖这些因素也要考虑
- 测试人员等相关人员需要提前锁定
具体到action上面,则可以考虑下下面这些:
- 日会了解每个人的进度、风险点、需要协助的点等
- 各个阶段的可运行单测是必须的
- 定期review代码(例如一周一次),check真实进度,owner或owner&相应开发人员参加即可
- 制定开发规范,保证代码风格统一
- 功能拆分尽可能细,一个功能点最好不要超过5天,尽量控制在3天之内
- 开发整体自测ok之后,对项目进行整体code review,同时提测
- code review之后修改的代码,全部修改完毕之后,要进行整体的回归测试,回归测试期间除bug问题,不允许再修改代码
- 发布避开大促封网,发布之前确定依赖方发布时间点,看下发布顺序有木有要求
其中,应重点关注项目中的风险,无论是何种原因,自己可控or不可控因素造成的,现状偏离计划的事情,都属于项目风险,应尽早抛出来,而且应尽可能保证你希望看到这一风险的人看到。其次,风险不是抛出来就完事了,还要考虑下是否可以cover掉这一风险,是否需要其他人协助,需要的话,也应尽早提出来。最后,尽可能多给测试留一些时间,你永远不知道测试过程中会发现什么问题。
5.交付清单
交付清单的意义不仅仅在于给到产品同学,让他check他所提的需求我们已实现,还在于我们自身对这个项目的一个回顾,另外,交付清单也可以给到测试同学一个最强王者辅助的作用,测试人员对比交付清单即可知道本次项目的所有功能,方便他们测试。所以,交付清单应尽可能详细,和TC 不冲突哦~
推荐思维导图+Excel+文字的形式展现。
6.发布前准备
主要是一些资源准备,例如线上服务器、线上DB、线上mq等等各种中间件及资源的准备。
其次,将项目中用到的SNAPSHOT 版本二方包替换为正式版二方包,替换完,记得再回归测试一下。
另外,还需要确定依赖的上下游的发布时间,如果此次发布依赖上下游的发布时间,需要和他们协商好具体的发布时间,确定到几点,以方便我们到点check他们是否发布,以决定我们是否可以发布。
咳咳,发布前也可以写一些工具,假如线上数据出现问题,可以通过这些工具修复数据。一名合格的数据卫士不应该直接订db,而应该通过工具来修复。项目上线,相应的工具也同步上线。
7.发布
发布过程中,需要看各种监控,确保此次发布没有问题,才能继续大范围发布。
发布完成,还应该有线上测试环节,以check线上功能可用。
同时,需要跟进几天线上监控、报警、日志等,确保没有问题后,才算此次发布顺利完成。
8.复盘
个人的复盘是必须的,原因我就不多说了。这里的复盘指的不是你对外分享/宣讲等等的复盘,而是对你内心那个真实的自己来讲的复盘,在这个项目中自己究竟有没有成长,成长了哪些,哪些地方做的好,哪些地方做的不好,不好的地方下次可不可以避免or解决,这个项目有没有偏离你的初衷等等。